SnapDAL Architectural Overview
virtualized databaseTODO: this is partially out of date. The concepts are correct, but some major refactoring has taken place. This page will be revamped as time permits
What is SnapDAL and more specifically, where does it fit into your architecture or well known application architectures such as n-tier? This could be discussed at great length but the simple answer is this: SnapDAL is completely architecture agnostic. You can use the tool in any architecture without compromising the basic tenants because SnapDAL is simply a utility library to make the process of coding and managing database access simpler. If you are coding a data layer for an n-tier modelled application, you could implement the data layer by using SnapDAL internally to make your database calls without exposing any portion of it's methods to your other tiers. If you are building a more traditional OO domain model, you could implement persistence using SnapDAL within your code. Although we are not aware of any Object Relationanal Mapper products that use SnapDAL, doing so would extend the abilities of SnapDAL to that tool. In particular, the unit testing functionality that SnapDAL provides would be a great benefit to any O/R tool, and to our knowledge, there are no tools available today that help at all with unit testing functionality.
SnapDAL is a technology choice, much like ADO.Net itself, that in turn can be used in any part of your application architecture where data access makes sense. Probably the most important point to get is that the term "Data Access Layer" implied by the DAL in the name SnapDAL does not mean the same thing as that term in the n-tier model. SnapDAL does not create a layer aware in any way of your application code, does not generate application specific code your business layer can call directly, does not manage your connections or transactions and does not automatically give you CRUD type actions around each table in your database. What it does do for you is to make all of these steps both easier to do, and possible to do in less lines of code. It will also make your database calls get executed in a more consistent fashion, in a way that neither coding standards or code generators can accomplish. Because of this, using SnapDAL has some interesting side effects on your application architecture. Since calls will be initiated and executed in a similar fashion, functionality such as tracing, logging, mapping of code to sql and call retries can be coded once and then used on *all* database calls. The specific functionality that SnapDAL will implement will be fleshed out over time, but understanding clearly how it fits into your applciation may help you determine if the tool is going to be beneficial or not to your applications.
First of all, just like ADO.net uses the Provider pattern to allow similar code to access a wide variety of databases, SnapDAL offers a way to do allow your application to build providers for it's specific data access calls. Because SnapDAL puts names on statements, rather than just putting the statement Sql in the text, you can use these names to put application specific terminology into your database calls and parameters. For example to setup CRUD routines for a specific database, you may want to use existing views, stored procs or queries to implement your data access. This may change over time as you tune the application. Wouldn't it be great to not worry about that fact in your application code? So that for the basic CRUD calls you just said, factory.ExecuteNonQuery("CreateCustomer", parms), factory.ExecuteDataReader("ReadCustomer", parms), factory.ExecuteNonQuery("UpdateCustomer", parms), factory("DeleteCustomer", parms)? Now, you or your dba can look at the real sql, change it using normal tools, and paste it back into the config file and your application will work exactly the same way. Because the information about your calls is saved in xml based files (metadata), you could easily use a tool like CodeSmith to parse your config files and build strongly typed commands like Dal.CreateCustomer(string customerId, ...); Between SnapDAL and the level of virtualization provided by normal database techniques such as views and stored procedures, you have full support for the idea of the database as a first class partner in your application, while at the same time from the point of view of your application, making the database appear as a simple command.
Architecturally, SnapDAL is used at different levels of detail depending on your need. The most likely use, and the one most tested, is to use the DataFactory to execute your database calls to a single database provider. You can fully use the functionality of SnapDAL without any knowledge of the other classes it provides. In this scenario, SnapDAL would be used much like many other data access helpers such as found in Microsoft's Data Access Application Block (DAAB), the other great factory based helper, DAC2 at CodeProject.com, or the ProviderFactory in the Mono project. Each has it's relative strengths and it would probably be some feature or another that would make you choose SnapDAL over some of the other options out there. SnapDAL works as well or better than each of these choices when viewed just as a simple data access helper.
Simple enough. Intialize a DataFactory with a connection, provider name such as SqlClient or Mock and specify a location for the statement files. After that calls are very simple. Pass a statement name to any of the calls, with optional input and output parameters, and you get back results in a Reader, or in scalars made of normal clr types. Beyond this however, you have much more control over the whole process. SnapDAL is based on the idea of using a Factory to produce Providers which in turn produce objects of the System.Data namespace. DataFactory is an instance that encapsulates a particular combination of provider type, a list of statements and connection string to simplify the code used to do common ADO.net operations. What SnapDAL looks like in reality is somewhat more complicated.
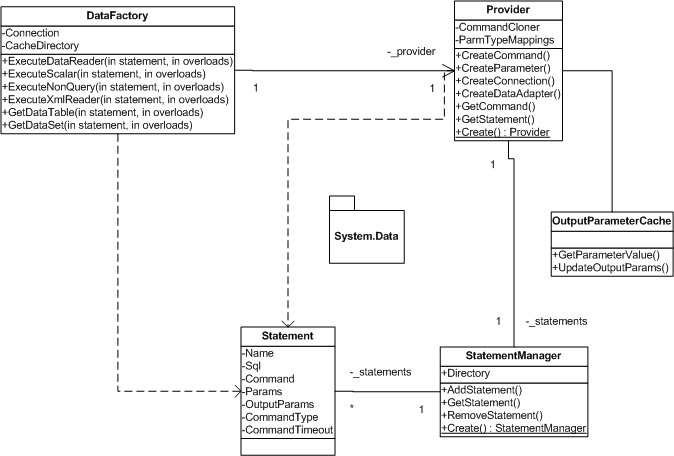
So, a DataFactory has a provider which has a cache which has a list of statements. The CacheDirectory is a DirectoryInfo that points to a directory of statement files. These files contain the actual implementation of the statement. In SnapDAL, you don't ExecuteDataReader with sql, you simply refer to a statement by name. The name is special, because it doubles as part of the filename the statement will appear as in the cache directory and the name of the statement in the config file. So, to have a statement "query_customer", your cache directory will have to have a file called query_customer.config and in that file must be a statement named query_customer.
Of course you can use the public methods of any class as provided and this is fully supported. You do need to understand some key elements of the architecture before you undertake this however. SnapDAL works with the assumption that a Statement is produced for every command that will be executed by DataFactory. There is just one exception and that is if you call the GetCommand() method of data factory. In this one case, there is an overload that allows you to create commands from the factory configured and ready to go like any normal IDbCommand. In general though, everything is built upon the idea of placing a statement in the cache, then cloning the Command that statement contains for execution. From any of the Executexxxx calls on the Data Factory, the provider is responsible for doing this for you. You can of course call the Provider yourself but as shown in the test, ReaderFromAlternateProvider, if you do this, you are responsible for cloning yourself. What happens if you don't clone your command? These command objects are available to all callers, not just the one you are interested in. Parameter values can be carried over. Timeout values which may have been reset, would not be expected values. You get the idea. If you pull instances from the cache, you should clone them before setting them up and making a call on them.
Notice on the Provider class, there is a property called CloneCommand. This property is a delegate that is called to clone the IDbCommand on the Statement during the GetStatement call. In the normal case, this delegate just does a memberwiseClone on the command object. This property is exposed however so that other techniques can be used. For example, the MockProvider class has it's own cloner that will tack on MockDataReader instances depending on test scenarios setup by the calling code. There is a wide variety of possibilities provided by this feature, not the least of which would be the ability to tack on AOP style decorators to do interceptions of all the IDbCommand calls. It should be possible in this way to do some interesting things like invalidating caches, post processing of readers (like doing a Rotate for example) or trace logging.
Each supported Provider, SqlClient, OleDb and Mock currently has a separate folder and namespace in the code. This is where provider specific code would go. For example, in the SqlClient provider there is code to go and take stored procedures in your database and generate config files for them. The SqlClient specific commands like those required for "For XML" database calls are also in the SqlClient folder. The Mock provider has specific methods that assist you during development.
Sharing statements between providers
SnapDAL has a mechanism to allow multiple providers to share the same statements where possilbe but to easily provide a provider specific version where the provider requires that. A good example is shown in the tests. OleDb and SqlClient with both accept named parameters. ODBC calls however use the order based syntax, like "? = exec sp_help ?, ?". Now within the cache directory all three providers support simple calls like "select * from customers". So the cache directory is organized like this.
root cache directory -- >SqlClient -- >OldDb -- >Mock -- >ODBC -- >any other provider
When the cache looks for a specific statement, it first looks in the subdirectory for the specific provider, OleDb for example. If it doesn't find the provider in that directory, it looks up one folder to the root directory of the cache. If it finds it there, it will use that statement. The effect of this is, put any statements that can be shared between providers in the root, and those specific to a provider in their sub folder.
SnapDAL supports providers other than the ones that are built in. In fact the Odbc provider, used in the unit tests and performance testing, is setup as a custom provider. To make this happen two things must happen. First of all, your provider must implement all of the basic ado.net classes. Documentation for this is available at microsoft, but most likely, all the major database vendors have already done this for you. Then in DataFactory.config, you would just add a provider definition. Look at the existing one which includes the ODBC provider setup the same way. One other important note. SnapDAL uses Activator.CreateInstance to create the first instance of the commands defined in DataFactory.config. The reason the provider must support the ADO.net recomendations is that the order of the parameters in the constructors must match the other providers, or clearly the provider will blow up when instantiated. Also, the provider must support an overload that accepts the DbType enum for parameters. This is the lowest common denominator that all providers can use in determining provider types. There is intial support in SnapDAL to have common clr types mapped to specific provider parameter types. In the case where the provider is loaded dynamically though, these types are mapped to DbType parameters. If this is a real burden, sign up on the developer list and let's talk. match that of the other